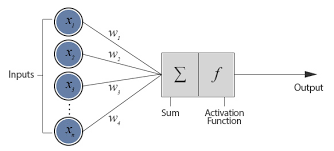
Feedforward Neural Networks formula
(activation function)
- FNN에서 activation function이 필요한 이유
⇒ Activation function의 기능은 일단 모델을 통과한 결과값을 비선형(0~1)값으로 변형시켜주는 역할을 한다. 그렇다면 왜 비선형 값으로 바꿔야 할까?
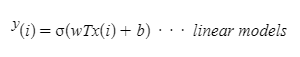
⇒ 모델의 layer을 2개를 쌓게 된다고 하는 경우 linear model 한층을 다음 linear model 한층을 또 지나게 되면 결과적으로 linear model이 된다. 최종 모델은 linear model이 되므로 복잡한 모델을 만들기엔 부적합하게 된다. (여러 layer을 쌓아도 딱히 의미가 없게 됨) 따라서 activation function을 통해 비선형 값으로 만들어 준다고 생각하면 된다.
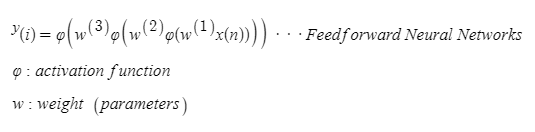
⇒ Activation function을 사용해 만들어진 모델 식은 위의 식처럼 weight(parameter)를 x(input)에 곱한 뒤 actionvation 처리 -> 이게 한 layer에 해당한다. 2개의 layer을 쌓고 싶다고 하는 경우 이것을 두번 반복하면 된다.
- Activation Function 종류

Deep learning 모델은 loss값 (예측값과 정답값의 차)를 최소화시키는 방향으로 진행되는데 이 과정에서 쓰이는 개념이 gradient descent와 back propagation이다. 둘의 과정을 통해 model의 parameter값을 update시킴으로서 손실함수값(loss)를 최소화시킨다.
- Gradient Descent
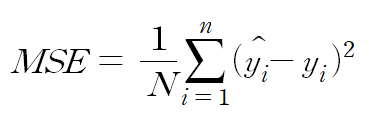
⇒ Gradient descent를 이해하기 위해선 loss function을 먼저 알아야하는데, 위의 식이 loss function의 method중 하나인 MSE 공식이다. y hat이 예측값이고 y가 정답값이라 할 때 둘의 차는 모델의 오차(loss)가 되고 둘의 차를 제곱한 것이 loss function이 된다.
⇒ 이 때 이 공식에서 가장 중요한 것은 x값은 parameter(weight)이다. 모델의 training의 목적은 오차가 가장 적은 weight값을 구하는 것이므로 위의 이차 함수 공식을 미분하여 y가 0이 되는 값이 손실을 최소화시키는 parameter를 얻어낼 수 있다.
⇒ 따라서 gradient descent는 미분해서 얻어지는 loss 함수의 최소값 weight이다.
- Back propagation
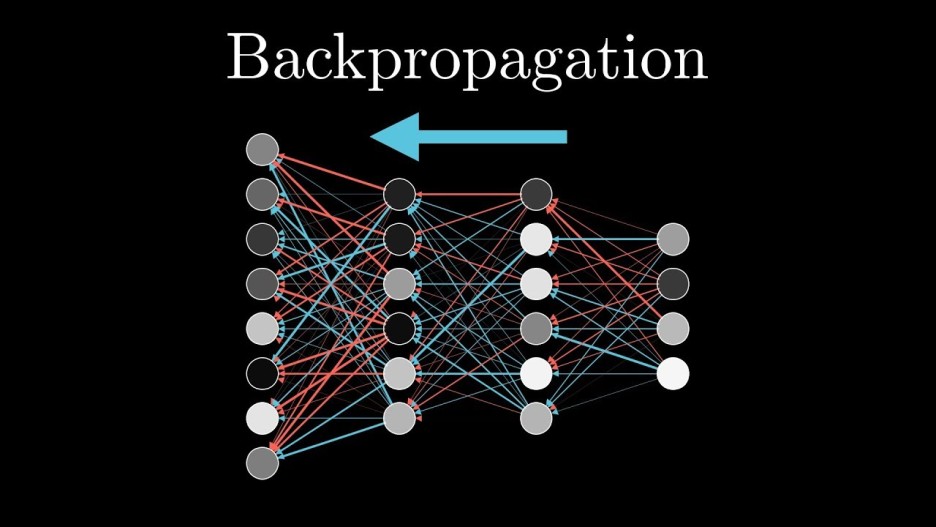
- Gradient descent 종류 :
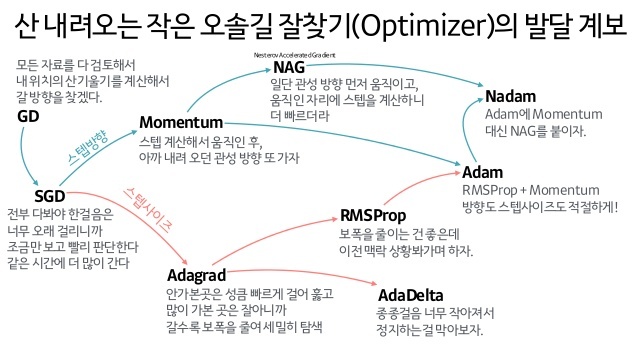
gradient descent 방법도 여러 가지가 있는데,
1) Stochastic gradient descent
: 모든 데이터를 사용하는 것이 아닌 random하게 mini-batch를 훈련시켜 gradient의 weight을 구해서 진행되는 방식
→ 문제점은 계산량이 너무 많아 속도가 떨어지고 noise가 섞인다는 단점이 있다.
2) Momentum
: SGD의 속도가 오래걸린다는 측면과 올바른 gradient 값에 도달할 때까지 다양하게 탐색해야 된다는 단점을 개선하기 위해 minibatch의 평균값을 구해 gradient값을 탐색하는 방식이다.
3) RMSProp
: SGD방식과 learning rate를 같이 활용한 방식으로, minibatch는 동일하나 parameter를 update할 때 learning rate를 곱해 반영한 방식이다.
4) ADAM = Momentum + RMSProp + bias correction
: 많이 쓰인 방법으로 momentum과 RMSProp의 장점을 모아놓은 method이다.
그외 성능 개선을 위한 여러 method
- Dropout
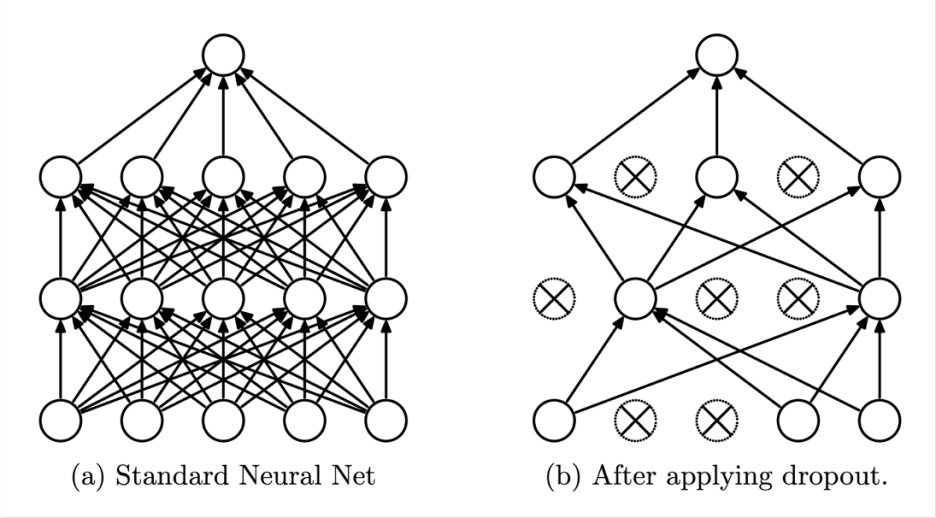
Overfitting이 발생하는 것을 방지하기 위해 쓰는 방법으로 위의 그림처럼 layer에서 몇몇개의 node를 제거하여 학습시키는 것이다. Deep neural network에 overfit 문제가 생기는 이유는 모든 node가 일하지 않아서 생기는데 이를 방지시키고자 node 몇개를 dropout시킨다고 보면 된다.
- Batch Normalization
Batch nomralization은 말그대로 batch당 normalization 0~1값으로 바구는 것으로, 하나의 layer을 추가하는 것과 동일하다. Batch normalization을 시행시키는 시점은 activation function에 넣기 전에 시행한다.
그리고, batch normalization을 쓰는 경우엔 dropout을 쓰지 않는다.